Text Extraction and Indexing Policy
Insight extracts and indexes searchable text from a wide range of file formats but cannot extract text in all circumstances. This policy is written to advise users as to Insight’s capability to extract and index text from files loaded into our system. See the Indexing Exceptions table for a full list of the indexing exceptions codes.
Acceptable File Formats
Insight can extract and index text from over 300 common file and document formats including:
Microsoft Office files
Most email file formats
WordPerfect files
Lotus files
Text files
In general, Insight can extract and index from most text-based file formats. For a comprehensive list of supported file formats see Supported Formats.
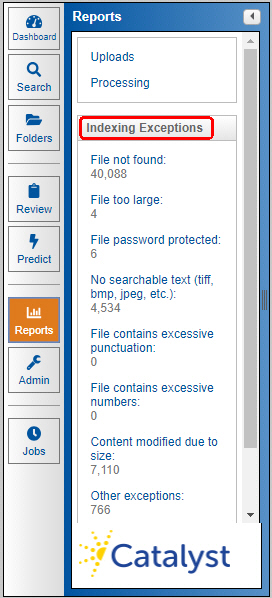
As might be expected, Insight cannot extract text from non-text file formats such as image or container files. In addition, there are a number of other cases where we prevent certain files from being ingested which allows us to quickly process your data and build your site. To view the excluded files by exception type, click the applicable Indexing Exception report from the Reports module in Insight.
The following is an explanation for each of Insight's Indexing exceptions.
Reports Module: Indexing Exceptions Links
When selected, the reports module displays the available reports which are linked in the navigation panel. The following is a brief description of each of the different Indexing Exceptions reports that can be run in Insight.
File not found
Documents where the file that is to be used for indexing is missing from the upload. To search for files that fall into the “File not found” group of exception-codes from the Free-Form Search-screen, users may enter the following search syntax into the Free Form search dialogue box: OrbError = [200]. This search query will return all of the documents that matched this code.
File too large
Insight will not index files that are deemed too large for efficient indexing. These files often consist of log files, large Excel files and large reports. Because the files can be detrimental to the performance of Insight’s indexing engine, we do not extract text from:
Any file that is over 256 MB will not be indexed (OrbError = [101 206]).
Any file where the extracted text is larger than the recommended size of Insight’s indexing engine, between 100 and 200 KB, will have its content evaluated. If the text does not contain excessive amounts of punctuation, numbers or unique characters it will be indexed.
To search for files that fall under the “File too large” error codes, search for (OrbError = [101 102 107 111 112 206]).
File password protected
This is for documents where our text extraction process determined the file is password protected and so the text cannot be extracted: (OrbError = 103).
No searchable text
As noted, certain files do not have any text to extract. We classify these documents in two different ways:
Image files, tiff, bmp, jpeg, etc., and containers, zip, rar, 7z, etc., (OrbError = 105).
Image only PDFs and other similar files (OrbError = 108).
To search for files that fall into the “No searchable text” error codes from the Free Form Search screen, search for OrbError = [105 108].
File contains excessive punctuation
Documents that fall under the "File contains excessive punctuation," indexing exception contain excessive punctuation marks as compared to the total number of terms. Examples of documents that may fall into this category are documents containing programming code, file listings, or other documents containing an excessive number of punctuation marks.
To search for files that fall into the “File contains excessive punctuation” error codes from search (OrbError = 113).
File contains excessive numbers
Documents that fall under the "File contains excessive numbers" indexing exceptions contain excessive numbers as compared to unique terms. Examples of documents that may fall into this category are spreadsheets, or other documents containing many numbers.
To search for files that fall into the “File contains excessive numbers” error codes search (OrbError = 114).
Content modified due to size
This link shows users documents with a large amount of text where we modify or "shrink" the amount of text by modifying the extracted text and removing certain non-alpha characters and/or removing duplicate words.
To search for files that fall into the “Content modified due to size” exception group, enter the following search syntax into the search dialogue box: indexissue:shrinkray
ATTN: This process is no longer used in the US as of March 22, 2018 (03-22-2018), so the "shrinkray" group of indexing exceptions will only apply to docs loaded into Insight prior to 03/22/2018 in the US. It is still used in Japan.
Other exceptions
To search for files that fall under the “Other exceptions” error codes from the Free Form Search screen, users may search for the exceptions using the following search: OrbError = [100 104 106 109 115 116 117 201 202 203 204] OR OrbError > 206. This is a catchall category that covers a number of indexing issues as follows:
Zero length file: This exception is for documents where the file is 0KB and so does not contain any data to extract (OrbError = 100).
Can't extract text: This is a general error code where our text extraction process can't extract text from a file, but there is no specific error (OrbError = 104).
Text won't go into indexing engine: This exception is for documents where our indexing engine just won’t accept the extracted text and so the extracted text must be removed to get the document into the indexing engine (OrbError = 106).
Text extraction took longer than 30 seconds: When text extraction takes longer than 30 seconds, the file or document will not be indexed (OrbError = 109).*
Note: OrbError codes 111-117 do not apply to documents loaded in Japan.
Too many bad characters or unique terms: These are documents that either contain an excessive number of unique terms or files with excessive amounts of base64 strings or files with specific non-Unicode characters that cause problems with Insight's indexing engine.
To search for files that fall under the "Other exceptions" error codes category from the Free Form Search screen, users would search for: OrbError = [115 116 117]
Why Insight has exceptions for documents with extractable text
To provide users with a high-performance solution, we identified several classes of problem files where the extracted text contains an excessive number of unique terms or tokens. Often this is the result of files containing characters extracted from an encrypted file, a file containing print script, computer code or even bad OCR.
These files are problematic for Insight’s indexing engine because the extracted text can bloat or corrupt the index and dramatically slow down performance as indexes are updated. They are typically not used for keyword searching because the extracted text is essentially gibberish.

