Insight Predict
Insight Predict is Catalyst's engine for Technology Assisted Review (TAR). It is based on a learning protocol called Continuous Active Learning (CAL). For details, refer to the ebook TAR for Smart People.
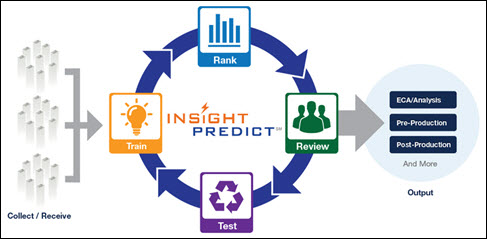
How Insight Predict Works
In the simplest terms, a set of documents is sent to Insight Predict. Some of them are reviewed by reviewers. Those reviewed documents are sent to a process (Predict’s algorithm), and that process helps to categorize the non-reviewed documents. Those non-reviewed documents are ordered (or ranked) from most likely relevant to least likely relevant, based on the decisions made on reviewed documents. The goal is to send the documents that are likely relevant to the review team, which will reduce the time and expense of reviewing non-relevant documents.
The initial review process is typically focused on locating responsive documents, but Insight Predict can identify other decisions such as issues, hot documents, privilege, or other information. For purposes of this guide, we will use “relevant” and “responsive” interchangeably, and assume that our goal is to find responsive documents.
There are several steps involved in this process. There is a continuous training stage, where the system is trained by reviewer decisions. The system ranks and re-ranks the collection of non-reviewed documents based on those decisions. Along the way, there are Quality Control (QC) steps in place to review contradictory coding calls, and real-time charts and statistics available to monitor progress. Decisions are made after systematic samples are taken and the ranking is verified.
Ranking
Ranking is the key to Insight Predict and is the method used to predict which documents are likely to be relevant. To rank documents, Insight Predict takes the coding information from the decision field (typically responsiveness) from a set of reviewed documents and puts the remainder of the document population in order, based on its likelihood of being relevant. Highly-ranked documents are likely to be relevant, while lower-ranked documents are not as likely to be relevant.
The system is trained by each reviewed document. As documents are reviewed, they are sent directly to the ranking algorithm, which re-ranks the collection of documents not yet reviewed. The system builds relationships between every word in every document, and every word in every other document in the collection.
So for example, if the word “contaminate” is a highly-ranked word in the documents designated as responsive, Insight Predict highly-ranks other documents that contain the word. It also finds other common words within the highly-ranked documents, which helps it identify key words in the population that might be meaningful and lead to other interesting documents.
Insight Predict continuously ranks the entire document collection.
Continuous Active Learning (CAL)
CAL differs from older TAR methods because it uses continuous learning throughout the entire review, rather than the one-time training that many systems use. Research shows that CAL is far more effective at finding relevant documents than earlier TAR protocols, which results in even bigger savings, by dramatically reducing review costs and review time.
Continuous Active Learning means that the training is continuous, rather than limited to discrete stages, and the learning approach is active rather than passive. The system does not rely on randomly selected documents for training.
In contrast, earlier versions of TAR required an expert, often a senior lawyer, to train the system themselves by clicking through thousands of documents to locate relevant ones, wasting a lot of time on non-relevant documents.

