Manage the QC and Systematic Stages
Within the Predict module, there are two validation stages, which you manage as you run your review:
QC stage: Provides a sample of coded documents for validation.
Systematic Random stage: Used to make decisions on a subset of ranked documents selected by the system.
QC Stage
The QC stage of the project is used to assign documents already reviewed for QC. The documents in this stage have been ranked by the system one way, but coded by reviewers in a different way (i.e., the most false positives and most false negatives according to the system).
To select documents for this stage, click the Get Documents button.
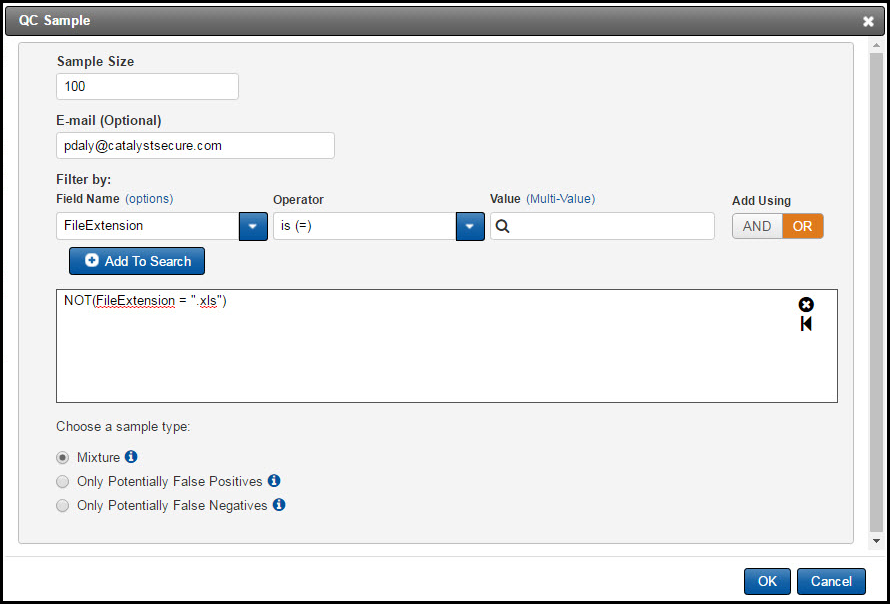
Next, select the desired sample size. The default is 100. There is also a filter to exclude documents. For example, if you want to exclude Excel files, you would use the syntax below.
Additional reports are available in this stage of the project and are helpful in identifying user coding and coding decisions that were overturned.
Choose a sample type. Mixture is the default. This means that the documents pulled are a mix of potentially false positive and potentially false negative. False positive documents are those the system believed would be coded as non-relevant (because they were ranked low) but the reviewer coded as relevant. False negative documents are those the system believed would be coded as relevant (because they were ranked high) but the reviewer coded as non-relevant. Choosing either of those options will give you 100% false negative or positive, rather than a mixture of both.
To access the QC Reports, click the Reports button.
The QC Report is similar to the Insight Document Audit Trail report but includes only the records in your project. It lists the fields that have been changed, the values changed in the field, and the user who made the change.
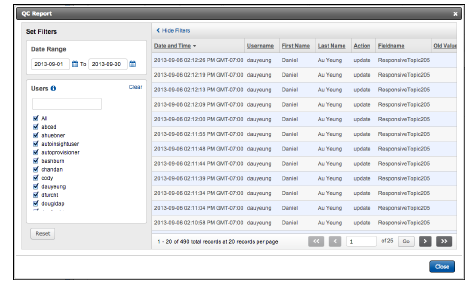
The date range is set to the current date, and all users are selected.
You can change the date range and select individual users or search for a specific user.
After documents go through the QC stage, those recoded in a different way, meaning that the decision was overturned by the QC reviewer, go back into the ranking engine. If there is no change in the Decision field, the document does not go back to ranking.
Systematic Random Sample
This Systematic Random stage of the project is used to determine a richness estimate and also to verify the training of the Predict algorithm. If this stages is used for verification, the results of the decisions in the stage produce a yield curve which allows you to determine a cutoff point for the review.
When the Systematic Random sample is taken, you are presented with the question “Is this sample going to be used for final validation?” If you answer “yes,” the ranking engine stops and no additional ranking takes place. Review can continue in the Review Module with no interruption. If you answer “no,” the ranking continues to happen. Answer “no” if you are using the sample for a richness estimate.
The documents pulled for the Systematic Random sample are selected by the system from the population of all non-reviewed documents in the project collection. Starting from the highest ranked document, the system identifies every Nth document to the lowest ranked. The set of documents used for this stage is taken from every point in the ranked set. The goal is to see if the system is correctly predicting whether or not the documents are accurately ranked.
After the Systematic stage is complete, meaning all the documents pulled are reviewed, a yield curve is created, which will help you see how well the documents were ranked. If appropriate, it will also help you determine where cutoff is appropriate for your situation. Consider using your expert reviewer in this stage. See Yield Curve for additional information.
Note that if you have not finished the Systematic sample of documents, the system will not allow you to create a yield curve and will ask you to finish the sample. And if the documents have been reviewed and are currently in the process of being ranked, the message will notify you that you cannot yet proceed with this stage until ranking is complete.
You will also generate a richness estimate from this stage. The richness estimate is based on your desired confidence level and margin of error.
To take a Systematic Random sample:
Answer the question when prompted: “Is this sample going to be used for final validation?” Then, select the desired sample size.
The default is 100.
Enter the Confidence Level and Margin of Error in order to help determine what your sample size should be.
The Predict Population Size is based on the number of documents in your Predict collection. If the number of documents changes over time due to rolling uploads or you have added or removed documents from your collection, these numbers will adjust.
The Confidence Level is defaulted to 95%. The Margin of Error is defaulted to 5%.
The number of documents in the Recommended Sample Size is based on your input.
You can accept the number at the Sample Size field, or change it to another value. Until this full set is reviewed and released, the Get Documents is disabled because the documents need to be reviewed and ranked before the next sample can be obtained. Once reviewed and ranked, it will be enabled again.
The richness estimate appears in your reports at Richness Estimate.
If you add documents to your Predict collection, you will be notified to take another Systematic Random sample and another richness estimate. The richness estimate is only accurate for the body of documents in the collection at the time you took the Systematic Random sample.
If you select the Copy sample to folder check box, the documents will be copied to a folder, rather than to the Systematic Random stage in Predict. If you use this option and review documents in a static folder, a yield curve will not be generated.

